引言:人工智能时代的技术浪潮
人工智能(AI)正以前所未有的速度重塑世界,从智能助手到自动驾驶,其应用已渗透到各行各业。对于零基础的初学者而言,进军人工智能领域可能看似 daunting,但通过系统化的学习和实践,掌握其核心技术与全流程体系是完全可行的。本教程旨在为你提供一个清晰的路线图,涵盖从基础概念到实战开发的全方位指南,特别聚焦自然语言处理(NLP)、GPT预训练和数据标注等关键技术,并介绍人工智能基础软件开发的要点。
第一章:人工智能基础概念与技术体系概览
人工智能的核心在于模拟人类智能,包括机器学习、深度学习和强化学习等子领域。全流程技术体系通常涉及以下环节:
- 问题定义与数据收集:明确AI任务目标,并获取相关数据集。
- 数据预处理与标注:清洗和格式化数据,为模型训练做准备。
- 模型选择与训练:根据任务选择算法(如神经网络),使用数据训练模型。
- 评估与优化:通过指标评估模型性能,并调整参数以提升效果。
- 部署与应用:将模型集成到实际系统中,如软件或硬件平台。
对于零基础者,建议从Python编程和数学基础(如线性代数、概率论)入手,逐步深入机器学习框架(如TensorFlow或PyTorch)。
第二章:自然语言处理(NLP)——让机器理解人类语言
NLP是AI的重要分支,专注于计算机与人类语言的交互。它涉及以下关键技术:
- 文本处理:包括分词、词性标注和句法分析,将原始文本转化为结构化数据。
- 语义理解:通过词嵌入(如Word2Vec)和上下文分析,捕捉词语含义和句子意图。
- 应用场景:如机器翻译、情感分析和智能客服,NLP技术已广泛应用于日常产品中。
入门NLP时,可从学习基础库(如NLTK或spaCy)开始,并尝试简单项目,如构建一个文本分类器。
第三章:GPT预训练——大语言模型的革命性突破
GPT(Generative Pre-trained Transformer)是一种基于Transformer架构的预训练模型,由OpenAI开发,代表了NLP领域的最新进展。它的核心概念包括:
- 预训练(Pre-training):模型在大量无标签文本数据上学习语言规律,通过预测下一个词的任务,构建对语言的通用理解。这类似于人类通过阅读积累知识。
- 微调(Fine-tuning):在预训练基础上,使用特定任务的数据(如问答或摘要)进一步训练模型,使其适应具体应用。
- 优势与影响:GPT模型如GPT-3能够生成流畅文本、回答问题甚至编写代码,推动了AI在创意和自动化领域的应用。对于初学者,理解GPT的原理有助于把握大模型时代的趋势,并可通过API接口(如OpenAI API)进行实战体验。
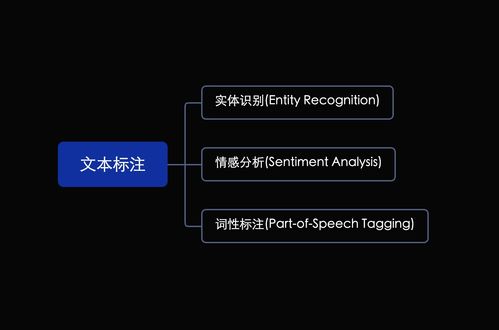
第四章:数据标注——AI模型的“燃料”与基石
数据标注是为原始数据添加标签或注释的过程,是监督学习的关键环节。在人工智能全流程中,高质量的数据标注直接影响模型性能:
- 什么是数据标注:例如,在图像识别中,标注图片中的物体;在NLP中,标注文本的情感或实体。
- 标注类型:包括分类标注、边界框标注和序列标注等,根据不同任务需求选择。
- 实践指南:零基础者可以从使用标注工具(如LabelImg或Prodigy)开始,参与开源项目或小型数据集标注,以理解数据质量的重要性。数据标注不仅是技术活,还涉及领域知识,是AI开发中不可或缺的一步。
第五章:人工智能基础软件开发——从理论到实战
掌握AI技术后,将其转化为实际软件产品是最终目标。基础软件开发涉及:
- 环境搭建:配置Python、框架(如PyTorch)和依赖库,确保开发环境稳定。
- 模型集成:将训练好的模型嵌入应用程序中,例如使用Flask或FastAPI构建Web服务。
- 性能优化:关注代码效率、内存管理和模型推理速度,以提升用户体验。
- 部署与维护:利用云平台(如AWS或Azure)部署模型,并持续监控和更新系统。
对于新手,建议从构建简单AI应用起步,如一个基于NLP的聊天机器人,通过实战加深对全流程的理解。开源社区和在线课程(如Coursera或动手学深度学习)是宝贵的学习资源。
持续学习与未来展望
人工智能领域日新月异,从零基础到精通需要耐心和实践。通过本教程,希望你已对全流程技术体系有了初步认识——从NLP和GPT预训练的理论核心,到数据标注的实操细节,再到软件开发的落地应用。记住,AI之旅是持续探索的过程:保持好奇心,参与项目实践,关注前沿研究(如多模态AI或伦理AI),你将在人工智能的浪潮中找到自己的位置。开始你的第一步吧,用代码和创意改变世界!