以深度学习为代表的人工智能技术正以前所未有的速度重塑世界,一场深刻的“AI革命”已全面展开。这场革命不仅体现为图像识别、自然语言处理等领域的性能飞跃,更在于其催生了全新的产业形态、研究范式与基础软件生态。本报告将聚焦深度学习驱动的AI革命,并深入剖析支撑其发展的基础软件开发前沿进展。
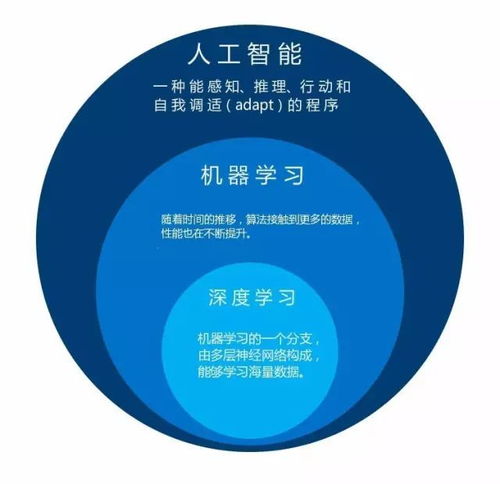
一、深度学习:AI革命的核心引擎
深度学习通过构建包含多层非线性变换的神经网络模型,能够从海量数据中自动学习层次化的特征表示,从而解决过去难以应对的复杂模式识别问题。其成功主要归功于三大要素:大规模数据、强大算力(尤其是GPU/TPU等专用硬件)以及算法创新。从AlphaGo的横空出世,到GPT系列、DALL-E等大模型的涌现,深度学习已从实验室走向千行百业,成为推动自动驾驶、智慧医疗、金融科技、内容生成等领域变革的核心技术。这场革命的特征是“智能化”的普适化与平民化,AI正从专用工具转变为通用能力基础设施。
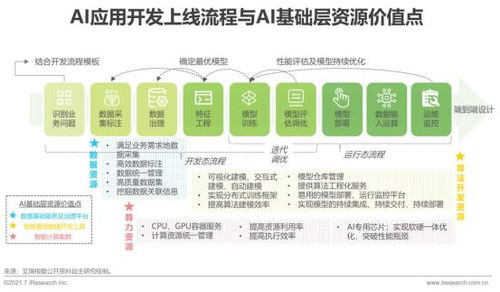
二、人工智能基础软件:生态基石与创新前沿
AI,尤其是深度学习的蓬勃发展,离不开底层基础软件栈的强力支撑。这一软件栈构成了从理论算法到产业应用的“转化桥梁”,其发展水平直接决定了AI创新的效率与边界。当前,AI基础软件开发呈现出以下关键趋势与前沿方向:
1. 框架与编译器:走向高性能与统一化
以TensorFlow、PyTorch、JAX等为代表的深度学习框架,通过提供灵活的编程接口和自动微分等核心功能,极大降低了模型研发门槛。前沿进展正聚焦于:
- 高性能计算与编译优化:如MLIR(Multi-Level Intermediate Representation)、TVM等编译器技术,致力于将高级模型描述自动优化并部署到CPU、GPU、NPU乃至各类边缘设备,实现“一次编写,随处高效运行”。
- 动态与静态图的融合:结合PyTorch的动态图易用性和TensorFlow静态图的部署优化优势,追求开发灵活性与运行效率的统一。
- 分布式训练规模化:支持千卡乃至万卡集群的稳定高效并行训练,是训练百亿、千亿参数大模型的关键。
2. 模型管理与部署:MLOps的工业化实践
随着模型生命周期管理的复杂化,MLOps理念应运而生,旨在实现AI模型的持续集成、持续交付与持续监控。相关基础软件包括:
- 模型仓库与版本管理:如MLflow、Weights & Biases,用于跟踪实验、管理模型版本和元数据。
- 自动化流水线:如Kubeflow、TFX,将数据预处理、训练、验证、部署流程自动化。
- 在线服务与推理优化:如Triton Inference Server,提供高性能、多框架的模型服务化能力;通过模型剪枝、量化、知识蒸馏等技术压缩模型,以满足边缘端低延迟、低功耗的部署需求。
- 数据与开发工具链:提升质量与效率
- 数据治理与版本控制:如Delta Lake、DVC,确保训练数据的一致性、可追溯性与可复现性。
- 自动化机器学习(AutoML):通过NAS(神经架构搜索)、超参数优化等工具,部分自动化模型设计过程,降低对专家经验的依赖。
- 交互式开发与可视化:Jupyter Notebook的普及以及更丰富的模型调试、可视化和可解释性工具(如Captum、TensorBoard),增强了开发过程的透明度和可控性。
4. 开源与标准化:构建协同生态
开源是AI基础软件发展的主旋律。从框架到工具,开源社区加速了技术迭代与知识共享。ONNX(开放神经网络交换格式)等标准致力于实现不同框架间模型的互操作性,避免生态锁定,促进工具链的健康发展。
三、挑战与未来展望
尽管成就显著,AI基础软件开发仍面临诸多挑战:系统复杂性剧增(软硬件协同设计)、安全与可信赖性(对抗攻击、隐私保护)、能源效率(大模型训练的巨大碳足迹)以及人才缺口。我们预期:
- AI原生基础设施:云计算将进化为“AI云”,提供从硬件、框架到模型服务的一体化、垂直优化的AI基础设施。
- 智能化编程:AI将更多地用于辅助甚至主导软件开发(如代码生成、调试),基础软件本身将变得更加“智能”。
- 软硬件深度协同:针对Transformer等主流架构的专用硬件及配套编译器将成主流,追求极致的性能功耗比。
- 重视可靠性与治理:伴随AI应用深入社会,基础软件将内置更多关于公平性、可解释性、鲁棒性和安全性的支持与审计工具。
###
深度学习掀起的AI革命方兴未艾,而其持续深化与广泛赋能,高度依赖于一个健壮、高效、易用的基础软件生态。这一领域的创新已从单一的框架竞争,演变为涵盖开发、部署、运维、治理的全栈竞争与合作。持续投资并突破AI基础软件的关键技术,不仅是抢占技术制高点的需要,更是确保AI革命成果能够稳健、公平、可持续地惠及全社会的基石。